The Linguistic Relativity of Programming
May 29, 2014
[This is a blog post expositing a talk I gave at BrooklynJS on May 15th, 2014. The slides can be found at bit.ly/bk-js.]
The hypothesis of linguistic relativity is a concept in linguistics that suggests that the languages we speak affect the way we think. While this viewpoint remains controversial across the academic linguistic community, it is easy for even someone not trained in linguistics to buy the idea. For example, it’s easy to appreciate that the words we have for colors carve a continuous color spectrum into discrete sections, which then influence the way we think about the color space.
But does this hypothesis apply to not just spoken languages but programming languages as well? I think so, that the programming languages we know strongly influence the way we think about programming. Yes, strongly. This is because there are key differences between programming languages and natural languages. Programming languages create and allow us to manipulate the space rather than just describe it. Natural languages are just a tool allowing us to describe and communicate about the world around them. By speaking, we aren’t changing the space. We aren’t in a Harry Potter novel, we don’t have the ability to say “accio book,” and the book will move off the shelf and towards us with our beck and call. However, by using programming languages, we are manipulating the space. Therefore, it makes sense that the programming languages we know would have more of an effect on the way we perceive and conceptualize of the programming environment than natural languages would have on the way we think about our natural environment.
Now I’m not the first person to think about how programming languages influence thought and are a tool of thought. Kenneth Iverson, a creator of the APL programming language wrote the following in his 1979 publication “Notation as a Tool of Thought”:
”Programming languages, because they were designed for the purpose of directing computers, offer important advantages as tools of thought. Not only are they universal…, but they are also executable and unambiguous.”
Furthermore, Paul Graham’s 2001 talk turned 2003 article entitled “Beating the Averages” included his infamous Blub Paradox also touches upon the idea that the programming languages we know constrain the way we are capable about thinking about programming. The main argument he makes, which he considers controversial, is that some programming languages are more powerful than others. The article is in large part about how using Lisp afforded him a competitive advantage over other companies because it was that much faster, that much more powerful. In his argument, he supposes a made-up, very average programming language called Blub. Blub programmers look down upon programming languages that are supposedly less powerful than Blub, thinking to themselves how silly those poor programmers are, how could they ever get by using such a weak language. It doesn’t even have feature x!. Programmers in more powerful languages than Blub, such as Lisps, look down upon Blub programmers the same way. However, Blub programmers look up at more powerful languages like Lisp and don’t see what all the fuss is about. They see a language of equal power to Blub but with some extra features they don’t understand, and if they don’t understand them, how useful could they be! They get along just fine with Blub, are able to solve all the problems they have as efficiently as they need. Graham goes on to evoke specific examples from his experiences:
”I look at [Python, Java, C, and Perl]. How can you get anything done in them, I think, without macros?”
(Aside: I am not a Lisp programmer, but Graham does a good job of explaining what macros are, enough to make this mere Blub programmer understand why they might be useful. I would suggesting reading other parts of the internet to learn about them, however.)
Graham continues:
“[T]hey’re satisfied with whatever language they happen to use, because it dictates the way they think about programs. I know this from my own experience, as a high school kid writing programs in Basic. That language didn’t even support recursion. It’s hard to imagine writing programs without using recursion, but I didn’t miss it at the time. I thought in Basic.”
Dijkstra had rather stronger things to say on the matter in his 1975 writing “How do we tell truths that might hurt”:
“It is practically impossible to teach good programming to students that have had a prior exposure to BASIC: as potential programmers they are mentally mutilated beyond hope of regeneration.”
While this salty piece of wit might have been to prove a point, it evokes an interesting thought. Does the first language you learn forever cloud the way you think about programming languages? Are we really “mentally mutilated beyond hope” if our first language was not Lisp?
I think not. Clearly Graham was able to overcome that his first language was (presumably) BASIC. He seems to have picked up on recursion and even macros! This severe constraint, however, is seen in natural languages. It is exceedingly difficult sometimes to fully grasp certain constructs and concepts in second languages, though, I would argue it is much easier to learn a second (and third and fourth) programming language. Relatedly, it’s pretty easy to understand other programming languages that are similar to those you know, which easier than in natural languages. For example, it is fairly easy for a Python programmer to work their day through a program written in Ruby. Because of this, I would like to propose that we are only “constrained” by the constructs and idioms of the most powerful programming language we know, not the language we’re necessarily using at the time and not the languages themselves.
This is, again, due to differences between natural and programming languages:
###1. We have the power to quickly learn more (powerful) programming languages and how to program in them idiomatically. It’s really hard to learn a new natural language if you’re not a kid, and if you don’t learn any language by a certain age, you are doomed to never learn any. However, I’d say the great majority of people only begin to program as adults, and we become pretty competent at it. We are even able to learn new languages and their idiomatic constructs after our first with relative ease. I first learned Java, and with that only really had one tool for manipulating data in an array: iteration. Then I learned Python and with it list comprehension. It seemed to flow naturally from iteration; I didn’t even realize it was a separate, arguably more powerful construct. Then, I went to Hacker School and many of my batchmates were functional programmers, exposing me to the great world of map and its associated acts. It took more time and brain twisting to finally grasp what was going on and the immutability in it all, but now it’s one of my favorite things, the first tool I reach for. I certainly feel the power in it.
###2. We can implement the constructs of more powerful languages as libraries in whatever language we use. This isn’t really an option in natural languages. It’s like those untranslatable words in foreign languages that we can’t quite translate to English. However, this translation is very possible in programming languages. We define our own words all the time! For example, the JavaScript library Underscore brought functional constructs to JavaScript before all browser implementations (dialects?) supported it. It doesn’t affect the Array prototype directly, but the underlying concept still remains. JavaScript programmers are no longer constricted by the JavaScript they were using, but rather if they knew the constructs of more powerful languages that had successfully implemented map and it’s functional friends across the board. With the excitement about the impending transition to ES6, transpilation is also an option, and with that programmers are whipping up modules to allow us to write ES6 features here and now. Lastly, Mozilla recently introduced a library called sweet.js that “brings the hygienic macros of languages like Scheme and Rust to JavaScript. Macros allow you to… craft the language you’ve always wanted.” The Lisp is now! Or really whatever other feature from whatever other programming language you could ever want…
###3. Programming languages themselves can change relatively quickly if we want them to. Natural languages evolve very slowly, over the course of centuries. Programming languages change much more quickly than that. When I was little, I used to imagine distinguished scholars sitting around a table discussing what words were going to go in English, very much the same the Declaration of Independence was born. While Strunk and White might have had their opinions, this is not actually the case with natural languages. However, it comes pretty close to the regulating and maintaining bodies that exist for programming languages. They have the power to suggest revisions and versions of languages and incorporate powerful aspects of other languages, which can be included as soon as we want them to be. This is because programming languages are synthetic— we make them up! While natural languages evolve in a similar way, with speakers borrowing words from other languages and maybe adopting them to the phonetic patterns of their own, adoption moves at a much more glacial pace. When I started learning JavaScript, of those methods I mentioned earlier for manipulating arrays of data, iteration and map seemed to be the only stable ways in the language, and map was actually just catching on as ES5 was gaining implementation marketshare. Now, ES6 is proposing the addition of list comprehension and even generators which are a powerful construct I’ve never used and still don’t completely grasp. I’d learned about them at a Python meetup, but didn’t quite understand them. I trust though I’ll be able to wrap my head around it eventually.
So what does that mean for Blub programmers?
While one ramification of this whole thing could be to go home right now, learn Clojure, and never look back (down?), I prefer to take a different route in tying this all together. Yes, you should go learn new languages that are radically different from those you’re used to; you’ll become a better programmer. But remain a polyglot. If you find something cool, bring it home and tell your friends, and make your favorite programming language that much richer.
Rah Rah Jekyll
April 16, 2014
Seriously, I got the majority of this setup on a train ride from Trenton, NJ to NYC. Jekyll is awesome.
Blogging Again Maybe?
April 15, 2014
I think I might start blogging again. Seems a good way to get some thoughts out on being a programmer…
Project: Synesthesia
December 3, 2012
[This was originally posted on an earlier blog of mine Linkguistics]
Recently in Hacker School, I finished a project using Python I called “Synesthesia.” The concept was devised by my housemate Natan, but it seemed to be an interesting engineering problem that would allow me to revisit my psycholinguistics knowledge. And then we can hang our art in our living room.
The concept: A generative art program into which you feed an image and you get back another image such that all the colored regions in the original are replaced with words that are related to that colors. So, a previously red patch might sport the words “cherry,” “communism,” and “balloon.” Here’s what happens:


This program has several parts, the logic behind each I will explain in more detail later. They are:
- Making the image’s color palette simpler based on what the user’s preferences. For the image above, I chose green, blue, orange, and black.
- Figuring out which words are related to those selected colors
- Putting the words where the colors are
###1. Simplifying the Image: imagesimpler.py In order to best figure out what words should go where, I needed to simplify the color space of the image. So, we as humans know that the blue section in the original above is all, well, blue. However, neighboring pixels in image are a) different colors and b) defined not by their names but by the amount of red, green, and blue they comprise. This trio is called the “RGB value.”
To do this, I used a nice module called webcolors that allowed me to make a list of the RGB value for each of the colors specified by the user. Then, I calculated the Euclidean distance between each pixel in the original image and the list of RGB values I’d created. Subsequently, I replaced the pixel with its nearest approximate, creating a simplified image.
###2. Related Words: cooccurrence.py In order to get a list of words that are related with the colors in the image, I appealed to the idea that related words co-occur with one another. I created a module that will find words that co-occur with any target word. To do this, I first scraped Wikipedia articles that come up when you do a search for the target word, compiling them all into a single corpus. I did this using Beautiful Soup. Following that, I created a frequency distribution of words that occur within a certain distance of the target word within it’s scraped corpus, seeing how many times each word appeared. I then used this distribution to determine which words co-occur significantly with the target.
###3. Creating the Art: synesthesizer.py To create the “synesthesized” image, I started at the top left corner, figured out what color the pixel was and popped the first word related to that color from the list of related words, and put in a new image in the corresponding space. Each letter in the word stood in for a pixel, and each word is separated by a space, which is also a pixel. The “color” of the word is determined by the color of the pixel-space it begins on. So, if the word “cat” were placed, the next word would begin 4 pixel-spaces after “cat” began. If the next word in line for the color doesn’t fit on the line, it’s put back in the stack and I start again at the new line. I know that’s a bit confusing, so here’s a visualization:
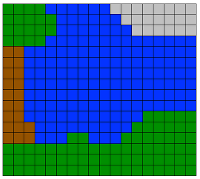

I admit that this is a lazy approach, which both muddles the image and makes the right side of the image have a terribly jagged border. I should perhaps create a dynamic programming algorithm (it’s a knapsack-y problem) that will pick words based on which ones with fit in the amount of the color that is left.
EDIT 12/5/12:
Writing this post and having to defend all my lazy design decisions made me realize that well, I was just being lazy and I could learn so much from actually solving the problem instead of just saying “close enough.” I wanted to fill in each line of color without wasting space or running off the edge of the color’s space. Sounds like a linear packing problem to me! A month of Hacker School has passed since I made my original (lazy) design decision, and in the past month, I’ve realized that I can solve any hard problem if I just work enough at it. Even an NP-hard problem!
I paired up with another Hacker Schooler, Betsy, because two brains are better than one, and we set to making a better painting algorithm. After joking a bit about solving the bin-packing problem and then getting a Field’s medal, we decided that just making this algorithm better would be sufficient, resigning to our O(n!) fate. The way to find the most optimal solution is to find all the solutions and choose the best one.
Quite expensive yes, but we know storage is our best friend. Because the corpuses from which the co-occurrences are calculated aren’t scraped freshly every time, we realized that we could store the results from our combinatorics in a pickled dictionary keyed by color and then by length, greatly reducing the online runtime. However, we realized that we didn’t need to calculate all of the combinations. We found only all combinations that are shorter than a certain number of characters (25), realizing that anything longer than that could be recursively split into two shorter segments which would have solutions within the dictionary. Then, when filling in the images line by line, we see how long each color segment is and then pop off the next word in from the “reconstituted” dictionary. In the event that a segment of color is shorter than any of the words, we put in exclamation points as a place holder. This method allowed us to reproduce the image extremely precisely, but we are going to look into different solutions.
Another little interesting problem I’ll touch on was that there were originally vertical bands of spaces running down the entirely orange segment in the Rothko you can see as the sample image above (the orange and blue one). We realized that this was because the line was always being split in half at the same place, leading to there being a space in the same place on each line at the junctions between the spliced segments. We added a random shift from 0 to 4 when splitting longer segments so to add noise and eliminate the band. Sweet!
It’s really exciting to me now that more detailed images actually look better now than ones that are less so, like the above Rothko. Look, it’s me!

Check it all out on github